

数直通DDN存储-英伟达SUPERPOD选择DDN公司存储方案,支持GPUDirect Storage(GDS)
发布时间:
2020-12-11 00:00
DDN公司打破自己的纪录成为超快的AI存储:在英伟达DGX 系统中以162 GiB/s向GPU直接传输数据,比NFS快60倍。DDN还是英伟达DGX SuperPOD参考架构的存储方案供应商。

随着一个机构的规模变大,如何确保其环境仍在理想状态下运行?在GPU基础设施、数据科学家、数据源的投资上是否做了优化来加速获取数据价值?谈到规模,简洁性和性能是密切相关的。AI项目的重要风险因素可能会存在于:管理数据竖井的复杂性、不同系统上的多层次存储,以及存储设备并非为大规模而设计。
多年的经验证明,DDN公司的存储产品能够用于大规模的生产环境。使用标准协议如NFS的存储方案是为中等规模的工作负载设计的,这些解决方案很难管理,而且架构无法扩展。即使采用ROCE这样的加速技术,NFS仍然是运行在GPU上的应用程序的瓶颈,特别是当GPU数量增加时。在这篇文章中,我们将讨论GPUDirect Storage(GDS)技术。DDN与英伟达公司密切合作一起推进这项先进技术,以确保DDN数据平台在DGX 系统和参考架构中能发挥更大作用,使SuperPOD成为企业立刻就可部署的产品。

许多机构都在想办法从人工智能中获得更有竞争力的价值,因此其数据设施必须为人工智能工作流提供更高水平的性能,并尽可能使用更少的数据设备和手工数据移动。DDN A³I存储方案优于其他方案,它通过高性能、易扩展,使配置的复杂性变得尽可能低。
在为全球先进的计算中心提供存储方案方面,DDN拥有数十年的经验,近期的一项部署是英伟达的Selene超级计算机。Selene由560个DGX 系统组成,在2020年11月的TOP500排行榜中排名第五,是目前正在运行的规模居首的SuperPOD。这些基于GPU的系统,以及所有的GPU计算平台,代表了海量数据处理的重大变革。
英伟达的 GPU提供了大规模的并发处理能力,而DDN公司的共享并行架构已被证明可以确保大规模的GPU上运行的各种非结构化数据工作负载 (大的、小的和混合文件类型的环境) 都可获得完全饱和的数据供给。这使得DDN公司的A³I解决方案成为实现深度学习和推理等端到端的人工智能工作流的理想数据平台。比如,DDN公司为世界上大规模自动驾驶项目提供了数据平台, 容量达几百PB,性能达TB/s。
但DDN和英伟达并不满足于已有的成绩,仍在继续寻求提高人工智能工作流性能的方法。两家公司合作的一项成果就是使用“GPUDirect Storage技术,GDS”来提高性能,GDS是NVIDIA的Magnum IO api中的一部分。GDS通过更快、更直接的数据路径提高了存储和GPU之间数据移动的效率。数据直接从主机上的网卡(NIC)传输到GPU,而不需要经过系统内存和CPU。这种方式消除了系统架构中IO路径瓶颈,减少了不必要的数据复制,降低了延迟,同时,释放出来的CPU资源可用于其他任务:比如深度学习应用中的图像处理。
英伟达的DGX 系统包括8个单独的Mellanox ConnectX6网络接口。为了管理DGX 内部的流量,有四个互连的PCI交换机,每个交换机连接两个GPU和两个网卡。四个PCI交换机通过两个AMD CPU互连。DDN公司完全集成了GDS, 并通过共享的并行架构确保数据通过靠近的接口直接传输,因此比其他供应商能更好地管理数据路径。可以说,DDN A³I存储与GDS的组合确保了数据在应用程序和存储之间通过更短、更有效的路径传输。
在过去6个月中,DDN公司为DGX 系统交付的存储配置是这样的:4台AI400X设备通过HDR 200 Infiniband网络与一台DGX 系统连接。DDN在实验室测试中也采用了相同的设备和配置,将DGX 系统上的8个网卡全都连接了,并与GPU保持较近。我们测量了使用全部8个GPU的性能:首先,通过CPU中的标准IO路径的性能;然后,启用GDS,通过优化的IO路径的性能。测试结果如下图:
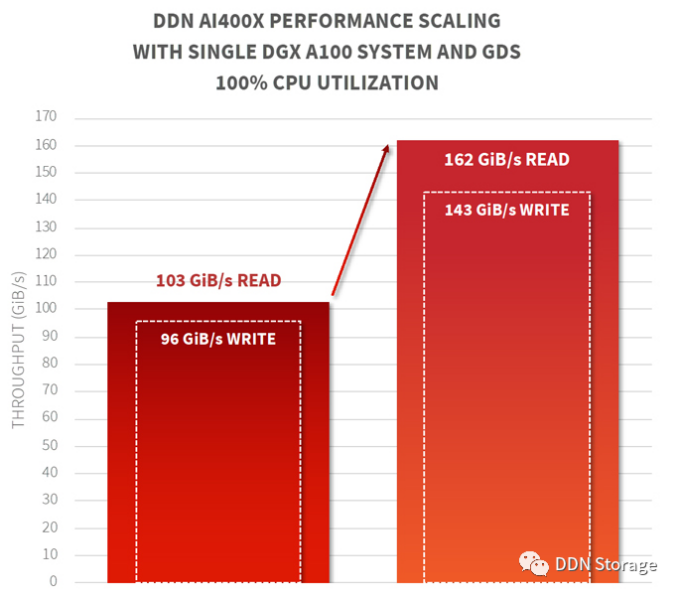
测试结果中有三个值得注意的地方:
一,通过GDS,DDN存储直接向GPU提供162 GiB/s的读性能和143 GiB/s的写性能。这几乎是8个HDR200网卡的全线速率能力!它比企业文件共享协议(如NFS)所能提供的性能高60倍。DDN共享并行体系结构的无限可扩展特性使其在同时使用多个DGX 系统的情况下(如POD或SuperPOD部署)也能达到同样级别的性能。
二,与通过CPU的传统数据路径相比,GDS使DDN存储能够为GPU多提供57%的吞吐量。尽管DDN存储通过CPU路径的性能也是很出色的-到一个客户端的读吞吐量达103 GiB/s,但毕竟受到路径的限制。加入GDS使DGX 上的GPU获得了更大的数据饱和度。
三,GDS已完全集成在DDN AI400X设备上,安装后无需后续更改。在8个GPU上运行的性能基准测试程序无缝地、即时地利用了DDN存储系统的GDS能力。开箱即用的DGX 系统可以立刻实现162 GiB/s性能,不涉及额外的许可或费用。
DDN的共享并行架构不断发展令人兴奋。A³I存储方案能够以高吞吐量、低延迟和大规模并发的方式传输数据, 无论是为单台DGX 系统,还是为多客户端的NVIDIA SuperPOD大型超级计算集群,DDN技术已被证明可以在任意规模上提供更大的灵活性和高性能。通过采用特有的多轨(MultiRail)算法,DDN A³I设备自动平衡网络流量,所以开箱即获得较好的高性能网络是A³I设备的一大特征。
相关新闻

暂无数据
